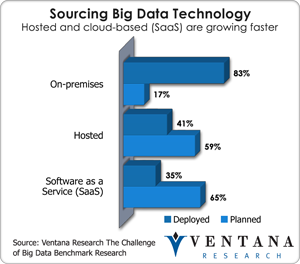
I had the pleasure of attending Cloudera’s recent analyst summit. Presenters reviewed the work the company has done since its founding six years ago and outlined its plans to use Hadoop to further empower big data technology to support what I call information optimization. Cloudera’s executive team has the co-founders of Hadoop who worked at Facebook, Oracle and Yahoo when they developed and used Hadoop. Last year they brought in CEO Tom Reilly, who led successful organizations at ArcSight, HP and IBM. Cloudera now has more than 500 employees, 800 partners and 40,000 users trained in its commercial version of Hadoop. The Hadoop technology has brought to the market an integration of computing, memory and disk storage; Cloudera has expanded the capabilities of this open source software for its customers through unique extension and commercialization of open source for enterprise use. The importance of big data is undisputed now: For example, our latest research in big data analytics finds it to be very important in 47 percent of organizations. However, we also find that only 14 percent are very satisfied with their use of big data, so there is plenty of room for improvement. How well Cloudera moves forward this year and next will determine its ability to compete in big data over the next five years.
Cloudera’s technology supports what it calls an enterprise data hub (EDH),  which ties together a series of integrated components for big data that include batch processing, analytic SQL, a search engine, machine learning, event stream processing and workload management; this is much like the way relational databases and tools evolved in the past. These features also can deal with the types of big data most often used, according to our research: 40 percent or more use five types, from transactional data (60%) to machine data (42%). Hadoop combines layers of the data and analytics stack from collection, staging and storage to data integration and integration with other technologies. For its part Cloudera has a sophisticated focus on both engineering and customer support. Its goal is to enable enterprise big data management that can connect and integrate with other data and applications from its range of partners. Cloudera also seeks to facilitate converged analytics. One of these partners, Zoomdata, demonstrated the potential of big data analytics in analytic discovery and exploration through its visualization on the Cloudera platform; its integrated and interactive tool can be used by business people as well as professionals in analytics, data management and IT.
which ties together a series of integrated components for big data that include batch processing, analytic SQL, a search engine, machine learning, event stream processing and workload management; this is much like the way relational databases and tools evolved in the past. These features also can deal with the types of big data most often used, according to our research: 40 percent or more use five types, from transactional data (60%) to machine data (42%). Hadoop combines layers of the data and analytics stack from collection, staging and storage to data integration and integration with other technologies. For its part Cloudera has a sophisticated focus on both engineering and customer support. Its goal is to enable enterprise big data management that can connect and integrate with other data and applications from its range of partners. Cloudera also seeks to facilitate converged analytics. One of these partners, Zoomdata, demonstrated the potential of big data analytics in analytic discovery and exploration through its visualization on the Cloudera platform; its integrated and interactive tool can be used by business people as well as professionals in analytics, data management and IT.
Cloudera latest major release with Cloudera Enterprise 5 brought a range of enterprise advancements from in-memory processing,  resource management, data management, data protection to name a few. Cloudera offers a range of product options that they announced to make it easier to embrace their Hadoop technology. Cloudera Express is its free version of Hadoop, and it provides three editions licensed through subscription: basic, flex and data hub. The Flex Edition of Cloudera Enterprise has support for analytic SQL, search, machine learning, event stream processing and online NoSQL through the Hadoop components HBase, Impala, Spark and Navigator; a customer organization can have one of these per Hadoop cluster. The Enterprise Data Hub (EDH) Edition enables use of any of the components in any configuration. Cloudera Navigator is a product for managing metadata, discovery and lineage, and in 2014 it will add search, annotation and registration on metadata. Cloudera uses Apache Hive to support SQL through HiveQL, and Cloudera Impala provides a unique interface to the Hadoop file system HDFS using SQL. This is in line with what our research shows organizations prefer: More than half (52%) use standard SQL to access Hadoop. This range of choices in getting to data within Hadoop helps Cloudera’s customers realize a broad range of uses that include predictive customer care, market risk management, customer experience and other areas where very large volumes of information can be applied for applications that were not cost-effective before. With EDH Edition Cloudera can compete directly with large players IBM, Oracle, SAS and Teradata, all of which have ambitions to provide the hub of big data operations for enterprises.
resource management, data management, data protection to name a few. Cloudera offers a range of product options that they announced to make it easier to embrace their Hadoop technology. Cloudera Express is its free version of Hadoop, and it provides three editions licensed through subscription: basic, flex and data hub. The Flex Edition of Cloudera Enterprise has support for analytic SQL, search, machine learning, event stream processing and online NoSQL through the Hadoop components HBase, Impala, Spark and Navigator; a customer organization can have one of these per Hadoop cluster. The Enterprise Data Hub (EDH) Edition enables use of any of the components in any configuration. Cloudera Navigator is a product for managing metadata, discovery and lineage, and in 2014 it will add search, annotation and registration on metadata. Cloudera uses Apache Hive to support SQL through HiveQL, and Cloudera Impala provides a unique interface to the Hadoop file system HDFS using SQL. This is in line with what our research shows organizations prefer: More than half (52%) use standard SQL to access Hadoop. This range of choices in getting to data within Hadoop helps Cloudera’s customers realize a broad range of uses that include predictive customer care, market risk management, customer experience and other areas where very large volumes of information can be applied for applications that were not cost-effective before. With EDH Edition Cloudera can compete directly with large players IBM, Oracle, SAS and Teradata, all of which have ambitions to provide the hub of big data operations for enterprises.
Having open source roots, community is especially important to Hadoop.  Part of building a community is providing training to certify and validate skills. Cloudera has enrolled more than 50,000 professionals in its Cloudera University and works with online learning provider Udacity to increase the number of certified Hadoop users. It also has developed academic relationships to promote Hadoop skills being taught to computer science students. Our research finds that this sort of activity is necessary: The most common challenge in big data analytics processes for two out of three (67%) organizations is not having enough skilled resources; we have found similar issues in the implementation and management of big data. The other aspect of a community is to enlist partners that offer specific capabilities. I am impressed with Cloudera’s range of partners, from OEMs and system integrators to channel resellers such as Cisco, Dell, HP, NetApp and Oracle to support in the cloud from Amazon, IBM, Verizon and others.
Part of building a community is providing training to certify and validate skills. Cloudera has enrolled more than 50,000 professionals in its Cloudera University and works with online learning provider Udacity to increase the number of certified Hadoop users. It also has developed academic relationships to promote Hadoop skills being taught to computer science students. Our research finds that this sort of activity is necessary: The most common challenge in big data analytics processes for two out of three (67%) organizations is not having enough skilled resources; we have found similar issues in the implementation and management of big data. The other aspect of a community is to enlist partners that offer specific capabilities. I am impressed with Cloudera’s range of partners, from OEMs and system integrators to channel resellers such as Cisco, Dell, HP, NetApp and Oracle to support in the cloud from Amazon, IBM, Verizon and others.
To help it keep up Cloudera announced it has raised another $160 million from the likes of T. Rowe Price, Michael Dell Ventures and Google Ventures to add to financing from venture capital firms. With this funding Cloudera outlined its investment focus for 2014 which will concentrate on advancing database and storage, security, in-memory computing and cloud deployment. I believe that it will need to go further to meet the growing needs for integration and analytics and prove that it can provide a high-value integrated offering directly as well as through partners. Investing in its Navigator product also is important, as our research finds that quality and consistency of data is the most challenging aspect of the big data analytics process in 56 percent of organizations. At the same time, Cloudera should focus on optimizing its infrastructure for the four types of data discovery that are required according to our analysis.
Cloudera’s advantage is being the focal point in the Hadoop ecosystem while others are still trying to match its numbers in developers and partners to serve big data needs. Our research finds substantial growth opportunity here: Hadoop will be used in 30  percent of organizations through 2015 and another 12 percent are planning to evaluate it. Our research also finds a significant lead for Cloudera in Hadoop distributions, but other options like Hortonworks and MapR are growing. The research finds that the most of these organizations are seeking the ability to respond faster to opportunities and threats; to do that they will need to have a next generation of skills to apply to big data projects. Our research in information optimization finds that over half (56%) of organizations are planning to use big data and Hadoop will be a key focus for those efforts. Cloudera has a strong position in the expanding big data market because it focuses on the fundamentals of information management and analytics through Hadoop. But it faces stiff competition from the established providers of RDBMSs and data appliances that are blending Hadoop with their technology as well as from a growing number of providers of commercial versions of Hadoop. Cloudera is well managed and has finances to meet these challenges; now it needs to be able to show many high-value production deployments in 2014 as the center of business’s big data strategies. If you are building a big data strategy with Hadoop, Cloudera must be in the evaluation priority for an organization.
percent of organizations through 2015 and another 12 percent are planning to evaluate it. Our research also finds a significant lead for Cloudera in Hadoop distributions, but other options like Hortonworks and MapR are growing. The research finds that the most of these organizations are seeking the ability to respond faster to opportunities and threats; to do that they will need to have a next generation of skills to apply to big data projects. Our research in information optimization finds that over half (56%) of organizations are planning to use big data and Hadoop will be a key focus for those efforts. Cloudera has a strong position in the expanding big data market because it focuses on the fundamentals of information management and analytics through Hadoop. But it faces stiff competition from the established providers of RDBMSs and data appliances that are blending Hadoop with their technology as well as from a growing number of providers of commercial versions of Hadoop. Cloudera is well managed and has finances to meet these challenges; now it needs to be able to show many high-value production deployments in 2014 as the center of business’s big data strategies. If you are building a big data strategy with Hadoop, Cloudera must be in the evaluation priority for an organization.
Regards,
Mark Smith
CEO & Chief Research Officer